
辉门东西(青岛)活塞有限公司访客…
辉门东西(青岛)活塞有限公司在活塞行业中处于领导地位,企业管理需…

山东亘元新材料股份有限公司访客…
山东亘元新材料股份有限公司是专业从事集功能性高新材料研发、生产…

中国信托业保障基金有限责任公司…
中国信托业保障基金有限责任公司是银行保险监会批准设立的银行业金…

陕西彬长矿业集团有限公司人脸识…
陕西彬长矿业集团有限公司为便于员工日常的各项管理,定制了一套钉…

校园一卡通系统的开发与安全实现
校园一卡通系统是以校园网为载体,以电子和信息技术为辅助手段,集… 【更多】
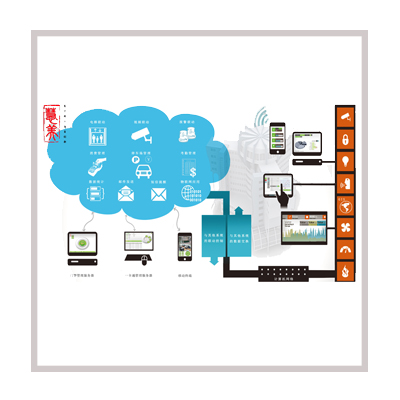
聊一聊现在很多公司用的会议预订…
随着科技的不断进步,传统的会议预订方式已经无法满足现代人的需求。
【更多】
会议预约系统软件为事业单位全面…
如今已步入快速发展时代,会议室是事业单位一个重要的战场。
【更多】

智慧园区停车场收费系统有哪些—…
智慧园区停车场收费系统是现代化城市管理中不可或缺的一部分,它不… 【更多】

互联网把全世界的知识搬进了人类的书房,人工智能将为人类提供合格的秘书,似乎留给人类的就剩下提出正确的需求了。
在全球掀起ChatGPT热潮之际,也涌现出许多对ChatGPT法律合规性的质疑之声,这些声音中有基于现有法律框架的分析,有从科技伦理角度的担忧,也有关于生成内容谬误的批评。在看过诸多批评质疑之后,作为一群科技领域的法律执业者,我们不禁好奇,ChatGPT是如何看待自身的法律合规风险的?
于是,我们尝试用ChatGPT写一篇关于其自身法律合规风险的文章。我们将人机合作写作本文的过程和结果尽量真实完整呈现出来,以此展示:ChatGPT是如何发挥作用的; ChatGPT本身存在哪些法律合规风险。
在故事的开始,我们在ChatGPT的问题输入框中,输入了这样一个要求:“写一篇关于ChatGPT合规风险的文章”。
ChatGPT做出了它的输出。
见图1、图2:

图1

图2
显然,按照我们的标准,这不是一篇合格的法律分析文章。它至少存在下列问题:1、就合规风险点而言,仅仅论述了数据隐私风险和生成内容合规风险,还有许多法律合规点没有列出;2、对于相关合规风险点的论述都只是点到为止,没有具体展开分析;3、文章结尾对ChatGPT合规风险的责任划分仅提及作为提供者的OpenAI,未涉及使用者和其他可能的责任方。
总结一句话就是,ChatGPT能够提供一个较为有逻辑的答案,但是内容的准确性和完备性没有保障。
ChatGPT独立完成写作任务失败,下面我们尝试通过人机合作来完成任务。
我们和ChatGPT的分工如下:
我们的任务:确定需要检索的内容,对资料进行过滤和整合,确定文章框架,文章审阅,排除谬误;ChatGPT的任务:内容检索,根据文章框架编写文章,根据审阅结果修订文章。
为了确保文章质量,符合法律执业者的基本职业要求,我们将人机合作写文章的过程细分为四步。
1、什么是ChatGPT?2、ChatGPT的合规风险?3、谁该为ChatGPT的违规行为负责?
Step 2:对检索资料的过滤及整合
用我们以法律执业者的眼光来看,ChatGPT检索出来的资料不仅存在重复和谬误,还有一个明显的问题就是每次回答总是不完整,需要我们反复追问,并且无法建立各个要点之间的逻辑联系。例如,最终列出的风险点是经过反复追问多次才得出,其中“监管风险”实际上与其他风险点是包含关系,不宜并列。
我们对ChatGPT输出的内容进行了整合,形成了文章框架,这相当于一个中间产品。
见图3:

图3
经过多次尝试,ChatGPT始终无法根据要求成文,这可能是其当前算法本身的局限性,也可能是账户权限低或者其他原因。因此,我们只好将文章内容要求拆分为一个个问题,由ChatGPT分别编写,我们做最后的整合。
对人机合作的最终成果,按照人类法律执业者的标准,仍然是不够深入和不够精致的,但是我们没有进行深度润色,因为我们希望比较真实地呈现人机合作的基本情况。
以下就是成果:
ChatGPT是一种由OpenAI训练的大型语言模型。它是基于Transformer架构,可以生成人类语言的文本,以回答问题、生成文章、对话等。ChatGPT经过大量的训练,能够模仿人类语言思维,并基于上下文进行自然的文本生成。它的训练数据来自互联网上的大量文本,使其能够涵盖多种语言风格和主题。总的来说,ChatGPT是一种高效的语言处理工具,可以支持许多自然语言处理应用。
ChatGPT的法律合规风险主要包括数据合规风险、内容违规风险、监管行政手续合规风险、知识产权风险、不当使用行为风险、道德和伦理风险、网络安全风险、国家安全风险。
数据合规风险
在训练、使用ChatGPT时需要收集大量的数据,这些数据可能是关键性、敏感性或者隐私性的,因此,必须确保数据合法地被收集、存储、使用和删除,以符合数据保护法律法规。主要有下列风险点:1、数据处理合规风险:使用的训练数据可能含有个人隐私数据,如用户个人医疗健康信息、个人金融信息等,输出的数据也可能会涉及个人隐私数据,在收集中需要保护这些数据不被滥用或泄露;2、数据完整性和准确性风险:ChatGPT使用的训练数据需要是准确和完整的,以保证ChatGPT的模型学习出的内容是正确的;3、数据技术安全风险:存储和使用的训练数据需要进行安全保护,防止数据被黑客攻击和窃取。
内容违规风险
ChatGPT生成的内容可能违反国内外的法律法规,例如,涉及欺诈、诽谤、诈骗、淫秽、儿童色情、赌博等内容,这些内容的生成可能给相关利益方造成损失,也可能对社会产生不利影响。主要有下列风险点:1、违法内容风险:ChatGPT不得生成违反当地法律法规的内容,包括但不限于涉及宣扬暴力、色情、儿童虐待、反对政府等内容;2、谬误内容风险:ChatGPT不得生成虚假、误导性或欺骗性信息,以此影响用户的判断和决策。
行政监管手续风险
OpenAI必须确保ChatGPT技术的使用和开发符合行政监管的要求,以避免违反监管备案和审批管理的相关法律法规,从而导致行政处罚。以中国为例,主要有下列监管手续要求:1、增值电信业务许可;2、算法备案;3、网络安全等级保护备案与测评。
知识产权风险
OpenAI和使用者必须确保ChatGPT的开发和使用不侵犯任何第三方的知识产权,以免产生知识产权纠纷和法律责任。主要有下列风险点:1、著作权风险:ChatGPT不得抄袭任何第三方的内容,包括但不限于文字、图片、音频等;ChatGPT输出的内容是否享有著作权以及著作权归属相关问题,需要依据个案情况以及各国的法律确定;2、商标授权风险:ChatGPT不得使用未经授权的商标或商号。
不当使用行为风险
不当使用ChatGPT,比如生成假消息、散播恶劣言论或滥用技术可能会造成恶劣影响,并导致法律诉讼和财务损失。主要有下列风险点:1、滥用技术风险:ChatGPT禁止用户滥用其服务,包括但不限于利用服务实施非法活动、干扰服务正常运行、自动发送垃圾邮件、生成虚假信息等;2、学术造假风险:ChatGPT应该采取一些预防措施,比如在使用前设置一些限制,不得在学术文章或者课件中使用,对检测出的不合规行为进行必要的惩罚等,以确保其在学术造假方面的合规。
道德和伦理风险
ChatGPT使用了复杂的算法,可能不够透明和公正,因此可能存在道德和伦理风险。如果算法存在偏见或不公正的因素,它们可能对生成的输出产生影响。开发者需要检查算法的透明度和公正性,以确保生成的输出不受偏见和不公正因素的影响。主要有下列风险点:1、强化偏见风险:必须尊重多元文化,不得以任何方式歧视任何种族、民族、宗教、性别、年龄、性取向、身体状况等;2、引导言论风险:不得发表任何带有违反法律、道德或偏见歧视性的言论;3、模型训练数据风险:需要公开数据来源和清晰明了的数据处理流程,以便对模型偏见进行评估;4、模型监管风险:要求有关方主动采取措施,以保证模型的适用性和公正性;5、用户使用环境风险:算法透明度需要确保模型的使用是公开的,同时要求使用环境合乎适用规范。
网络安全风险
ChatGPT在生成和存储大量敏感数据时,可能成为黑客和恶意软件的目标,导致数据泄露和信息安全威胁。主要有下列风险点:1、网络安全风险:使用者需要确保网络连接的安全性,以防止攻击者获取数据;2、技术审核风险:使用者需要确保使用的技术符合合法、安全、合规的标准。
国家安全风险
ChatGPT技术可能对国家安全和国防构成威胁。主要有下列风险点:1、国家安全信息风险:应该禁止ChatGPT帮助使用者收集影响国家安全的信息;2、国家安全活动风险:应该禁止ChatGPT帮助使用者制定危害国家安全的计划或给出相应建议。
ChatGPT的违规行为的主要责任方包括:开发者(OpenAI、其他技术平台提供商)、使用者(包括决策者)、第三方评估机构和训练数据提供者。在确保ChatGPT的合规性方面,这些责任方必须加强对ChatGPT的监督,并确保它不侵犯任何法律法规和道德准则。
开发者
开发者是指制作和发布ChatGPT的机构,包括OpenAI和其他技术平台提供商。他们应该对ChatGPT的技术质量和安全负责,以确保ChatGPT符合相关法律法规和道德标准。他们还需要定期评估ChatGPT的风险并进行相关风险管理,以确保ChatGPT的使用是安全、合法和道德的。
使用者
使用者是指使用ChatGPT的个人或组织,他们在使用ChatGPT时也需要遵守相关法律法规和道德标准。使用者需要对ChatGPT的使用方式负责,并确保ChatGPT不被用于违反法律法规和道德标准的活动。决策者(比如组织的领导和管理者)需要确保组织内的ChatGPT使用符合法律法规和道德标准。
第三方评估机构
第三方评估机构是指独立于ChatGPT开发者和使用者之外的机构,他们负责对ChatGPT进行客观、公正的评估和评价。他们需要对ChatGPT的技术质量、合规性和安全性等方面进行评估,以确保ChatGPT符合相关法律法规和道德标准。
训练数据提供者
训练数据提供者是指向ChatGPT模型提供数据的用户或者其他人员。训练数据内容的正确性和合法性直接影响系统的输出是否合规;训练数据来源的合法性也需要训练数据提供者负责,否则也会导致数据合规问题的出现。例如,如果训练数据是通过非法爬取、未经个人同意等违规途径收集而来,则系统的输出内容也因为来源的不合规而不具备合法性基础;如果训练数据中包含极端、诽谤、歧视、骚扰或任何其他违法行为,系统很可能在输出内容时产生违法行为。
总之,ChatGPT合规风险是一个需要认真对待的问题。只有在上述各个方面的多重保障下,才能确保ChatGPT在未来的长期可持续发展。
经过多次尝试,ChatGPT始终无法一次生成关于它自身法律合规风险的合格文章,即使在我们介入后,它对法律专业问题回答的表现也不尽如人意,需要我们仔细地勘误、修改和润色。因此,现阶段ChatGPT仅能做一些查找线索、检索资料和初步润色的工作。
不过,在我们逐渐熟悉并深入地使用ChatGPT后,我们也感觉到,ChatGPT具有成为强大法律检索工具的潜力。我们问的问题越精确,其回答的谬误越少,并且其归纳总结的信息还能够对我们起到提示和建议的效果。它就像一个思维怪诞的秘书,你无法完全信任它,但是也能从它的答案中有所收获。
至少在现阶段,ChatGPT还不会取代法律执业者。但假以时日, ChatGPT及其类似产品不断地提高其生成内容的准确性,将逐渐成为强大的工具,而使用者的认知和思维决定着其生成内容价值的上限。这就应了那句话:你不会被AI取代,但你可能会被熟练使用AI的人取代。(作者:袁立志 罗澄杰 陈东旭,单位:北京竞天公诚律师事务所)
责编:金国中
来源:新华社客户端
声明:本网站部分的文章、图片及材料来源于互联网,如有侵权请联系撤删,谢谢!
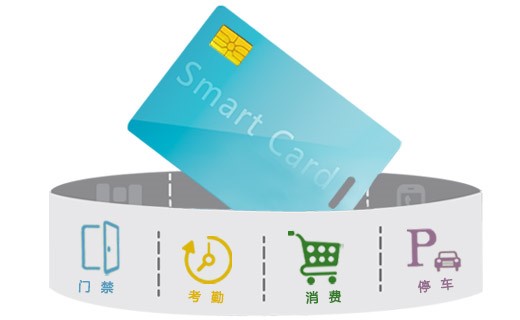
智慧一卡通系统 http://www.wisemax.cn
感谢您的关注,详细产品内容,可拨打北京慧美鑫业科技有限公司客服电话:010-64484490进行资询。更多资讯,敬请扫码关注我公司微信公众号:

慧于精工、美自创新
全国服务热线
010-64484490
13601076290






